1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
| import requests
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
from wordcloud import WordCloud
from PIL import Image
import jieba
import matplotlib.pyplot as plt
import re
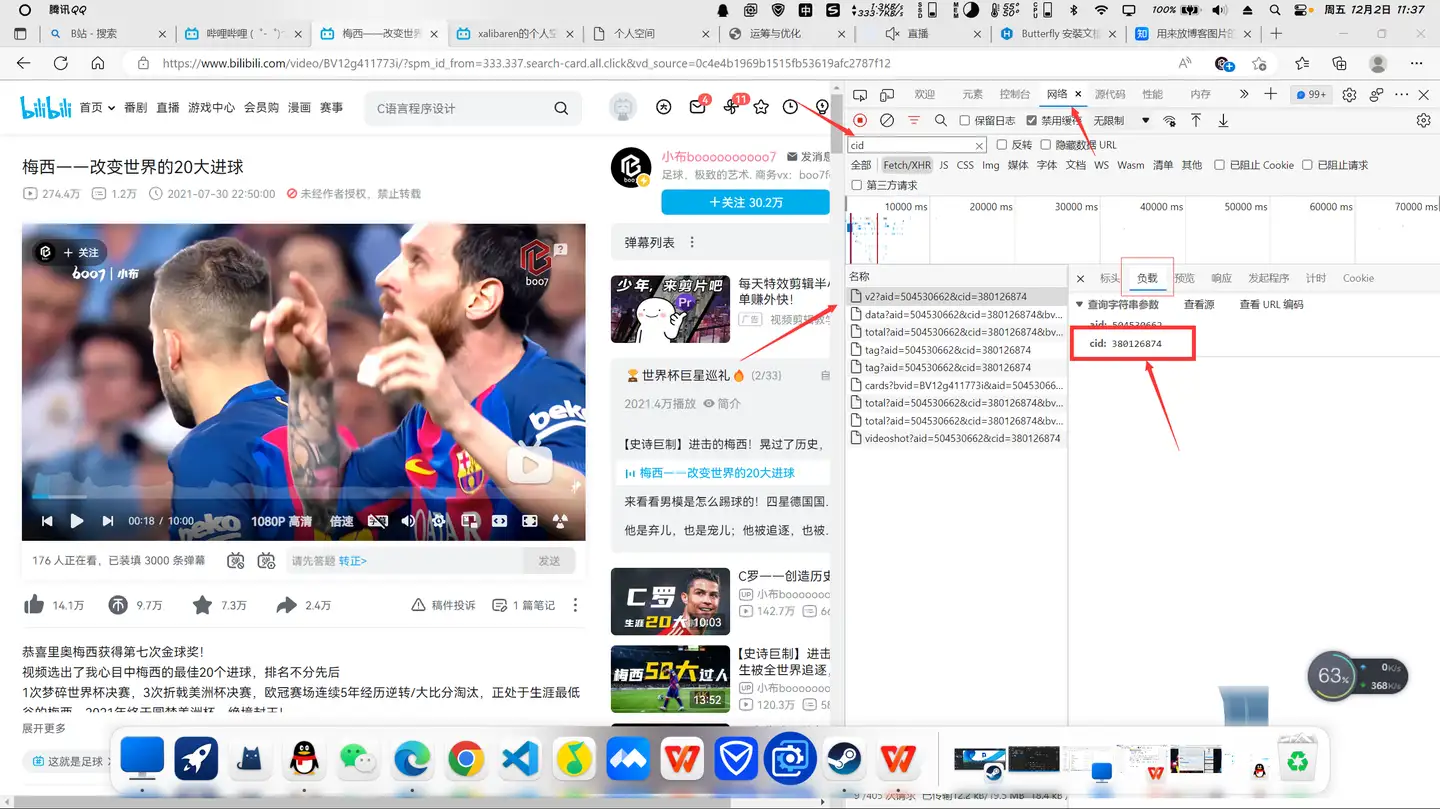
def get_contents(cid):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.56'}
url = "https://comment.bilibili.com/"+str(cid)+".xml"
req = requests.get(url=url,headers=header)
html_byte = req.content
html_str = str(html_byte,"utf-8")
soup = BeautifulSoup(html_str,'html.parser')
results = soup.find_all('d')
contents = [x.text for x in results]
return contents
def creat_xlsx(xlsx_filename):
file_xlsx = open(str(xlsx_filename) + '.xlsx','w')
file_xlsx.close()
def creat_txt(txt_filename):
file_txt = open(str(txt_filename) + '.txt','w')
file_txt.close()
def download_excel(contents,xlsx_filename):
dic ={"contents" : contents}
df = pd.DataFrame(dic)
df["contents"].to_excel(str(xlsx_filename)+".xlsx")
def download_open_txt(contents,txt_filename):
with open(str(txt_filename)+".txt", 'w', encoding='utf-8') as f:
for i in contents:
f.write(i+"\n")
with open(str(txt_filename)+".txt",encoding="utf-8") as f:
s = f.read()
return s
def washword(s):
text = ' '.join(jieba.cut(s))
data = re.findall('[\u4e00-\u9fa5]+', text)
text1 = ' '.join(data)
return text1
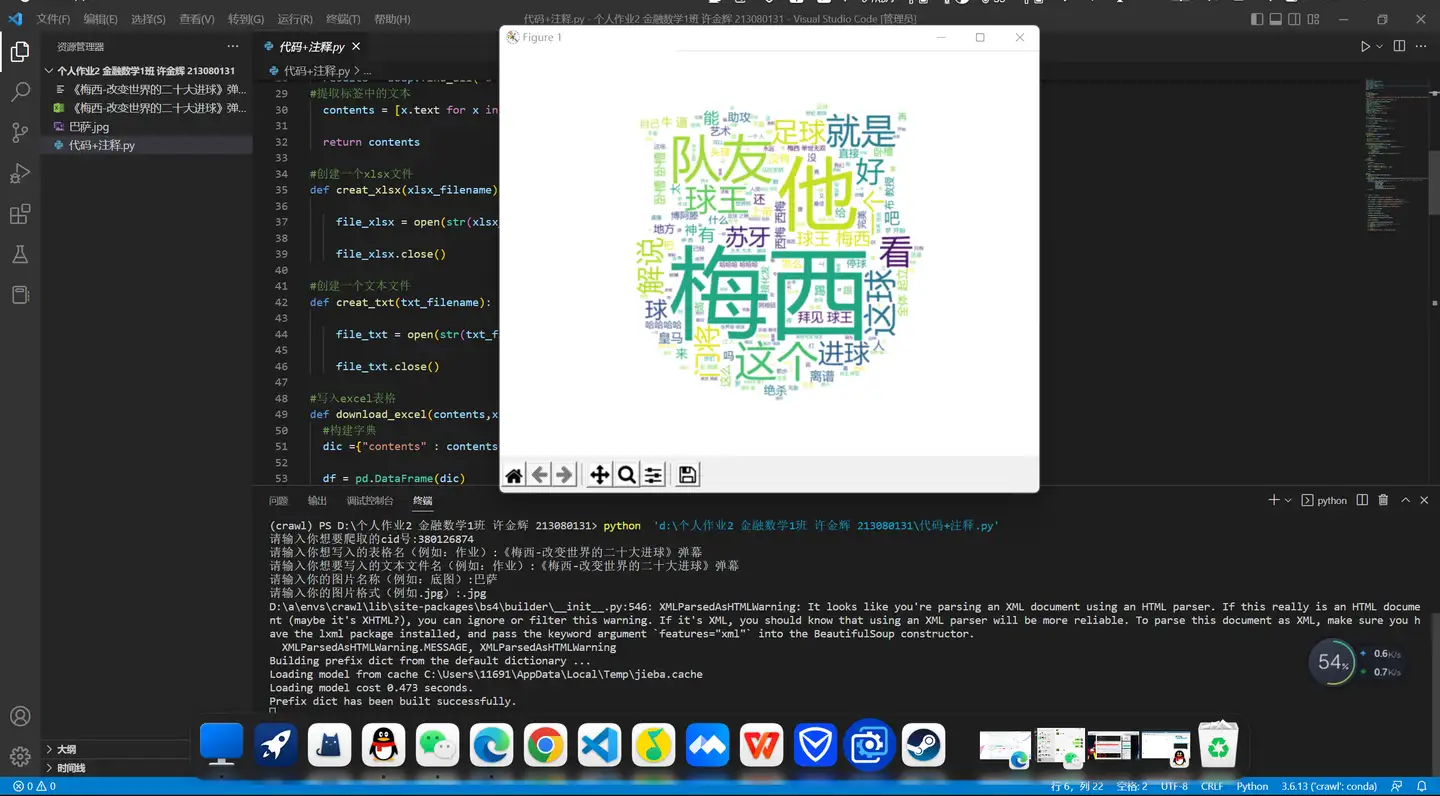
def wordcloud(text1,img_filename,img_format):
mask_imag=np.array(Image.open(str(img_filename)+str(img_format)))
stopwords = ["我","你","她","的","是","了","在","也","和","就","都","这","啊","真的","不","看球"]
wc = WordCloud(font_path="msyh.ttc",
mask=mask_imag,
width = 1000,
height = 700,
background_color='white',
max_words=200,
stopwords=stopwords).generate(text1)
return wc
if __name__ == '__main__':
cid = int(input("请输入你想要爬取的cid号:"))
xlsx_filename = str(input("请输入你想写入的表格名(例如:作业):"))
txt_filename = str(input("请输入你想要写入的文本文件名(例如:作业):"))
img_filename = str(input("请输入你的图片名称(例如:底图):"))
img_format = str(input("请输入你的图片格式(例如.jpg):"))
creat_xlsx(xlsx_filename)
creat_txt(txt_filename)
contents = get_contents(cid)
download_excel(contents,xlsx_filename)
s = download_open_txt(contents,txt_filename)
text1 =washword(s)
wc = wordcloud(text1,img_filename,img_format)
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()
wc.to_file("《梅西-改变世界二十大进球》弹幕.png")
|