
爬虫-scrapy框架介绍及基础指令
作者:下里巴人
前言:
这个学期,博主有一门课叫做“数据采集技术”,于是我在暑假自学的爬虫又开始攻击我了(doge。这篇博客就暂且作为我复习爬虫的开始吧o(╥﹏╥)o,如题所述,接下来就开始scrapy框架的介绍和基础指令!
一.Scrapy框架介绍

1.简介
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
2.架构
- Scrapy Engine(引擎):
负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。 - Scheduler(调度器):
它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。 - Downloader(下载器):
负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。 - Spider(爬虫):
它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。 - Item Pipeline(管道):
它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。 - Downloader Middlewares(下载中间件):
一个可以自定义扩展下载功能的组件。 - Spider Middlewares(Spider中间件):
一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
流程示意图
博主是在b站尚硅谷自学的scrapy框架,在他的教程中有一张简易化的框架图,我略作优化,放在下面哈,也许会更有助于大家的理解。
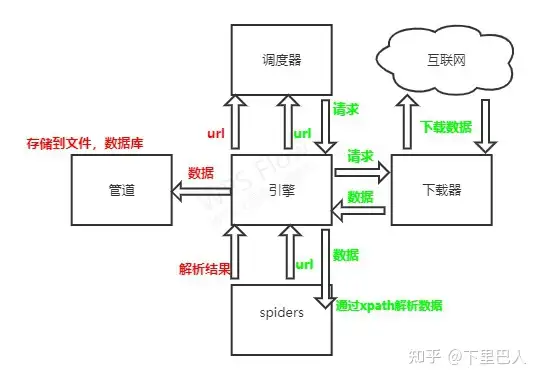
3.工作原理
- 引擎向spiders要url
- 引擎将要爬取的url给调度器
- 调度器会将url生成请求对象放入到指定的队列中
- 从队列中出队一个请求
- 引擎将请求交给下载器进行处理
- 下载器发送请求获取互联网数据
- 下载器将数据返回给引擎
- 引擎将数据再次给到spiders
- spiders通过xpath解析该数据,得到数据或者url
- spiders将数据或url给到引擎
- 引擎判断该数据是url还是数据,是数据,交给管道(item pipeline)处理,是url交给调度器处理
二.工具准备
1.Python环境及Scrapy、lxml库下载(vscode为例)
以博主为例,我使用的python版本为3.6.13;Scrapy版本为 2.6.1
在终端中输入以下指令,来下载scrapy,lxml库
1 | pip install scrapy |
如果想指定下载版本可以输入以下指令(以2.6.1为例)
1 | pip install scrapy==2.6.1 |
下载后输入以下指令看是否成功,如果成功会出现这样的画面:
1 | scrapy --version |
2.xpath插件
Xpath介绍

XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。
我们可以下载一个浏览器的xpath辅助插件,可以帮助我们确实语法正确与否,并反馈给我们可以解析到的数据,具体安装教程我放在下面。
注:不同的浏览器需要安装不同的插件,以自己喜好为准哦!
这也是我们需要提前学习的,十分简单,但是需要基础的html语法知识,用他来解析html十分的简洁,xpath语法的学习文档我会放在下面,可以去学习一下哦!https://blog.csdn.net/weixin_64471900/article/details/124314236
三.基础指令
创建爬虫项目
首先,一定是创建爬虫项目,在终端中输入以下指令:
1 | scrapy startproject 项目名称 |
注:不能以数字开头 也不能包含中文
这时,你会发现当前文件夹目录下出现了一个新的文件夹,文件夹名字为你刚刚输入的 项目名称。这代表项目已经创建成功啦!
创建爬虫文件
首先,我们要将自己的终端切换到我们的爬虫文件中,在终端中输入以下指令:
1 | cd 项目名称\项目名称\spiders |
接着,我们要创建文件,在终端中继续输入:
1 | scrapy genspider 爬虫文件的名字 要爬的网页 |
注:文件名和项目名不能相同,否则会报错
例子:
1 | scrapy genspider ceshi1 www.baidu.com |
注:一般情况不需要添加http协议 因为start_url的值是根据allowed_domains的值修改的 当起始url结尾是html是 需要去掉/
这是你可以看到,项目文件夹下的spider文件夹中,多出了一个你命名的新文件,其中内容类似于:
1 | import scrapy |
具体含义及用法会在下一篇中介绍,到这里我们已经成功完成了爬虫文件的建立
此时爬虫文件夹架构介绍
在完成上一步后,我们可以看到新创建好的项目文件夹下有很多我们不认识的文件,他们的意思是什么呢,我们来简单介绍一下:
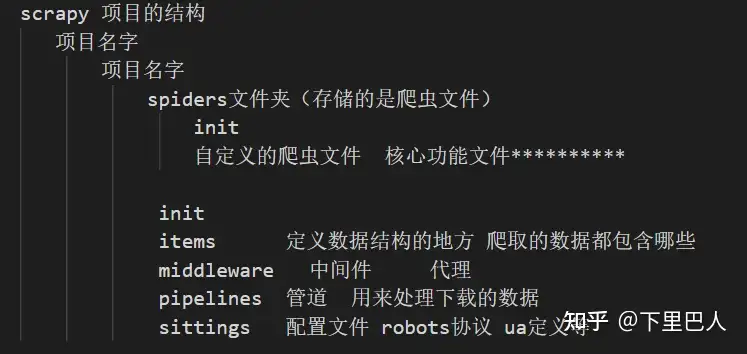
运行爬虫文件
当你完成了一份爬虫文件,想要运行调试怎么办?请在终端中输入以下指令:
1 | scrapy crawl 爬虫文件的名字 |
即可运行
好啦,这篇文章就到此为止了,相信通过上面的叙述你应该可以自主的创建一个爬虫项目了,至于如何开始真正的项目,下一篇博客就会以一个例子作为介绍,我也有点忘了,先让我复习一波(doge



